计算机如何理解单词:一个单词向量入门
我的计算机到底如何理解单词? 如果您认为有人藏在您的计算机中,那么我们将为您提供消息!那没有。 但是,有一种非常复杂的算法,非常聪明的数据科学家使用这种东西创建了这种算法 称为词向量。
什么是词向量引物?
尽管许多自然语言处理(NLP)算法提供了理解单词和短语的外观,但是这些算法主要用于数字空间中单词的表示。 在NLP中,我们称这些表示为词向量。您可以将向量看作是计算机在特定学习语言的上下文中理解的单词的拼写。 以下博客文章简要介绍了什么是词向量以及如何在NLP研究中使用它们。
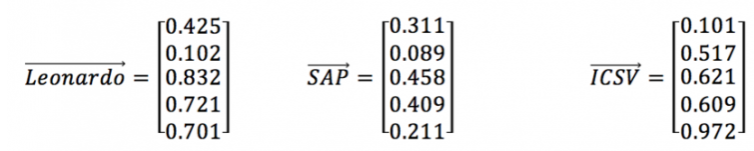
词向量的例子
单词向量使计算机可以像处理数字值一样处理单词,从而使执行操作和比较它们变得容易。 生成的数字空间特定于所使用的训练数据集。 如果上面显示的向量用在经过不同语料集训练的数字空间中,则数字向量可能指的是完全不同的词。
与普通话一样,单个单词本身并没有多大意义,但与其他单词组合在一起时具有含义和上下文。 单词向量的工作方式相同。 它们在其他向量的上下文中具有意义。 用于生成数字空间的训练语料库的内容将对单词的联想/含义产生影响。
这很直观,与我们学习语言的方式相似。 例如,如果允许一个孩子(算法)阅读(处理)的唯一书籍(语料库)是“绿鸡蛋和火腿”,而这个孩子(算法)从未有鸡蛋,则该孩子(算法)可能会认为形容词“ 绿色”通常与名词“鸡蛋”相关联,并且可以假设鸡蛋是绿色的。 这个数字空间内的单词向量的方向包含有关矢量化单词的含义信息。
非常相似的单词具有指向相似方向的向量。 Kings和Kaisers都是欧洲男性皇室成员; 他们的单词向量将指向相似的方向。 以类似于真实单词的方式,单词矢量可以通过矢量操作串在一起,并且仍然保留含义。 考虑普遍存在的“国王”,“女王”,“男人”和“女人”的例子。 假设您想提到的皇室贵族就像国王,但女人而不是男人。 在经过适当训练的单词向量集中,这些向量操作将使计算机知道您所指的是女王。
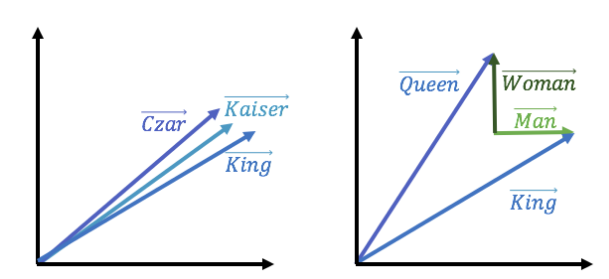
计算机如何学习单词向量集可能会对NLP算法在表示真实语音方面的有效性产生重大影响。 正在迅速进行NLP计算和关联的后台,以查找您键入的单词的数值。 根据这些关联,您的NLP引擎可能会比其他引擎表现更好。 这一切都与数据的上下文和质量有关,这也是一件好事! 您不希望您的计算机从商店订购绿色鸡蛋……这根本没有意思!
词汇表
语料库: 大量非结构化文档,可作为自然语言处理算法的训练材料。
自然语言处理:能够理解并产生人类语音/语言的应用数学模型。
词向量:数字空间中的分布式单词表示形式,用于捕获词汇中的语义关联。
NLP如何教计算机单词的含义
人类擅长对话。当某人说某事时,我们能理解他的意思,当银行这样的词在金融机构或河岸的语境中使用时,我们也能理解。我们使用逻辑、语言、情感推理和理解的力量来回应对话。为了让机器像我们一样真正理解自然语言,我们的第一个任务是教它们单词的意义,这是一个说起来容易做起来难的任务。过去几年在这一领域取得了重大进展。我们的第一站比基于神经网络的表现更早。在这个阶段,我们试图教计算机单词或n-gram的存在和不存在。一种简单的方法是使用one-hot编码。
one-hot 编码向量
单词在计算机上的表示方式是单词向量的形式。 词向量的最简单形式之一是一热编码向量。 为了理解这个概念,假设我们有一个非常小的词汇表,其中包括:魔术(magic),龙(dragon),国王(king),皇后(queen)。 龙这个词的一个热编码向量看起来像这样:
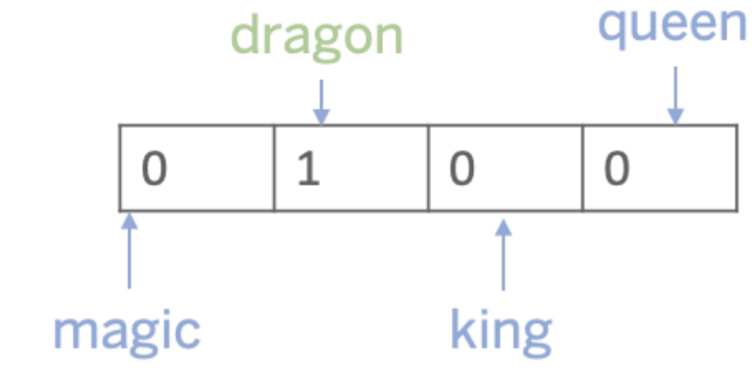
使用这样的编码,除了在句子中出现和不出现单词外,不会捕捉到任何东西。但是在这篇文章后面所描述的表现是建立在这个想法上的。
词袋模型(BoW)
文档中的每个单词或n-gram都链接到矢量索引。 根据单词的存在或不存在,我们用向量索引在文档中出现的次数来标记向量索引。 该技术广泛用于文档分类。 例如,如果我们将这两个字符串作为文档,“The quick brown fox jumped over the lazy dog.(快速的棕色狐狸跳过了懒惰的狗。)”和“The dog woke up and started chasing the fox.(这只狗醒来并开始追逐狐狸。)”我们可以像下面所示的那样组成一个字典:
然后用每个文档中单词的计数来形成向量。在本例中,我们得到了一个13个元素的向量,每个文档都是这样的。
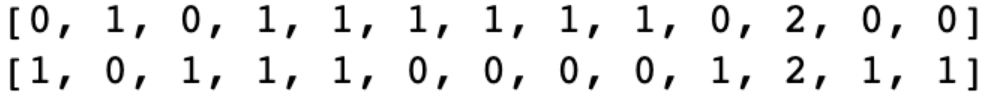
该方法的局限性在于它会导致极大的特征尺寸和稀疏矢量。 但是,当您只想用几行代码创建基线模型并且数据集较小时,仍可以使用此模型。
TF-IDF
由于BoW只关心单词的出现频率,因此我们在TF – IDF方面迈出了一步。 这是自然语言处理领域中的一种流行算法,并且是术语频率-逆文档频率的缩写。 它衡量单词或n-gram对语料库中文档的重要性。
文档中的每个单词都有一个分数,该分数随着单词在文档中的出现频率的增加而成比例地增加,但是如果在语料库中太频繁地出现该分数,则会被抵消。TF-IDF值可以用来代替上述向量中的频率计数。由于这是一种统计方法,它仍然不能捕捉单词的含义。

尽管这两种技术有助于解决NLP中的许多问题,但它们仍然没有抓住单词的真实含义。著名的语言学家J·R·弗斯(J.R.Firth)说:``单词的完整含义总是与上下文相关的,除了上下文以外,对任何含义的研究都不能被认真对待。’’ 学习单词嵌入或向量的最简单方法之一是使用神经网络。
基于神经网络的嵌入
基于一个词只能在其使用的语境中被完全定义的概念;词嵌入( Word Embeddings)是一种方法来表示一个词的基础上,它的公司保持。在构建单词嵌入时,我们的目标是开发密集的向量表示,以某种方式捕获它们在文档中出现的不同上下文中的含义。在前面的方法中,我们仅使用向量的一个索引来显示单词的存在、不存在或计数。在下面的方法中,我们将转向分布表示。这个表达式使用了整个长度。
Word2Vec
创建分布向量的最流行的方法之一是Word2Vec。它是由Mikolov等人于2013年在谷歌开发的。他们提出了两种不同的方法,连续词包法和连续跳跃图法。为了理解这两个体系结构是如何工作的,让我们来看一下这个示例段落:
“Harry Potter is by J. K. Rowling, a British author. It is named for its protagonist and hero, the fictional Harry Potter. The seven books in the series have sold over 500 million copies across the world in over 70 languages and is the best-selling book series of all time. All of them have been made into movies.(《哈利·波特》是英国作家j·k·罗琳的作品。它是以主人公和英雄哈利·波特的名字命名的。该系列的七本书以70多种语言在全球售出了5亿本,是有史以来最畅销的系列书籍。他们都被拍成了电影。)”
连续词袋(Continuous Bag of Words ,CBOW)
该体系结构旨在根据输入上下文来预测当前单词。 想象一下一个滑动窗口,该窗口在上一段中从一个单词移动到另一个单词。 当窗口位于“幻想”一词上方时,其前面的单词和该单词之后的单词均视为该单词的上下文。

一个one-hot编码的上下文词向量是这个模型的输入。向量的维数为语料库词汇量V。该模型由一个隐层和一个输出层组成。该模型的训练目标是使输出字的条件概率最大。因此,改变W1和W2的权值,直到模型能够实现输出字的高条件概率。
所以,在我们的例子中,给定前四个单词’a’,’series’,’of’, ‘eight’和后四个单词-‘novel’,’and’,’eight’,’movies’的一个热编码向量,上面所示的CBOW模型是为了最大化在输出层获得’fantasy’的条件概率。应该注意的是,上下文单词输入网络的顺序并不重要。
连续跳过模型(Continuous Skip Grams )
这个模型与CBOW模型相反。这里,给定一个单词,我们想要预测它通常出现的上下文。以下是该架构的外观:
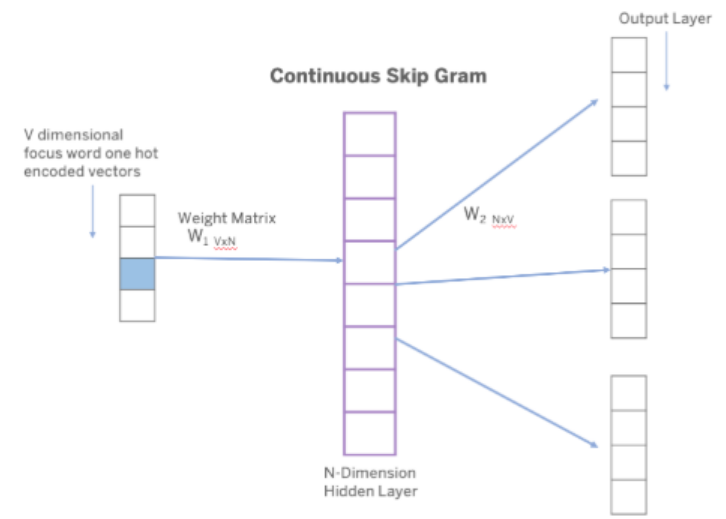
该模型将输出C个V维向量。C定义为我们希望模型返回的上下文单词的数量,V定义为前一个模型中的总词汇量。对模型进行了训练,使预测误差最小化。因此,当我们对模型的输入是fantasy时,我们期望它返回许多你通常在其中找到fantasy的单词的向量。需要注意的是,当我们增加C时,模型给出了更好的词向量。
CBOW训练更简单、速度更快,而连续跳跃图模型对不常见单词的训练效果更好。即使我们训练了这两个模型,我们也没有使用它们。我们感兴趣的是模型结束时的权值W。用权矩阵W2表示的权值就变成了我们的字向量。这些词向量然后可以用来初始化神经网络训练执行不同的任务。
Word2Vec并不是产生连续分布字向量结构的模型,但他们是第一个降低计算复杂度的模型。单词向量的质量取决于用于训练它们的语料库。 Word2Vec最初在Google新闻数据集中接受了16亿个高频单词的训练。 因此,单词向量学习新闻报道领域中使用单词的上下文。
GloVe和fastText — NLP中的两个流行的词向量模型
Miklov等人通过展示两种主要的方法:跳跃图和连续单词包(CBOW),向世界介绍了单词向量的力量。不久之后,在这些方法的基础上发现了两种更流行的单词嵌入方法。我们将讨论GloVe和fastText,它们是NLP世界中非常流行的单词向量模型。
全局词向量(Global Vectors ,GloVe )
彭宁顿等有人认为word2vec使用的在线扫描方法不是最优的,因为它没有完全利用有关单词共现的全局统计信息。
在他们称之为全局向量(GloVe)的模型中,他们说:该模型产生了一个具有有意义的子结构的向量空间,其在最近一次单词类比任务中的表现为75%。它在相似度任务和命名实体识别方面也优于相关模型
为了了解GloVe的工作方式,我们需要了解GloVe建立在两种主要方法上-全局矩阵分解和局部上下文窗口。
在NLP中,全局矩阵分解是使用线性代数的矩阵分解方法来减少长期频率矩阵的过程。 这些矩阵通常表示文档中单词的出现或不存在。 应用于术语频率矩阵的全局矩阵分解被称为潜在语义分析(LSA)。
本地上下文窗口方法有CBOW和Skip Gram。跳跃图可以很好地处理少量的训练数据,甚至可以表示被认为是罕见的单词,而CBOW训练速度要快几倍,对于频繁出现的单词的准确性也略好一些。
这篇论文的作者提到,与其学习原始的共现概率,学习这些共现概率的比率更有用。这有助于更好地区分术语相关性中的细微差别,并提高单词类比任务的性能。
它是这样工作的:不是从旨在执行不同任务(例如预测相邻词(CBOW)或预测焦点词(Skip-Gram))的神经网络中提取嵌入内容,而是直接优化嵌入内容,以便 两个单词向量的点积等于两个单词彼此靠近出现的次数的对数。
例如,如果两个单词cat和dog出现在彼此的上下文中,那么在文档语料库中一个10个单词的窗口中出现20次:
Vector(cat) . Vector(dog) = log(10)
这就迫使模型对出现在它们附近的单词的频率分布进行编码。
fasttext
fastText是word2vec模型的扩展,是另一种单词嵌入方法。fastText并不直接学习单词的向量,而是将每个单词表示为n-gram字符。例如,以n=3的单词artificial为例,这个单词的fastText表示为<ar, art, rti, tif, ifi, fic, ici, ial, al>,其中的尖括号表示单词的开头和结尾。
这有助于捕获较短单词的含义,并允许嵌入理解后缀和前缀。一旦单词用字符n-gram表示,就会训练一个跳跃图模型来学习嵌入。这个模型被认为是一个单词包模型,在单词上有一个滑动窗口,因为没有考虑单词的内部结构。只要字符在这个窗口内,n-gram的顺序就无关紧要。
fastText可以很好地处理罕见的单词。所以即使一个单词在训练中没有出现,它也可以被分解成n-gram来得到它的嵌入。
Word2vec和GloVe都无法为模型字典之外的单词提供任何向量表示。这是这种方法的一个巨大优势。
结论
我们已经看到了不同的向量方法。GloVe向我们展示了如何利用包含在文档中的全球统计信息。然而,fastText是建立在word2vec模型上的,而不是考虑单词,而是考虑子单词。你可能会问哪种模型是最好的。这取决于你的数据和你要解决的问题
本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!